


Index Roundup
Index is a roundup of engineering blogs, research and talks from engineers in the search and AI community. We welcome contributions to the roundup, please share any relevant content or your work.
Hey, I’m Julie on the product team at Rockset, a search and analytics database, and have teamed up with search consultant Jettro Coenradie to create the Index roundup. Here’s what we’re featuring in the inaugural edition:
DoorDash’s new search engine
Recommended reads
Using small language models to improve search relevance at Swiggy
RAFT for adding domain-specific knowledge to language models
Evaluating GenAI products at LinkedIn
Automate customer interaction using OpenAI Assistants
Tips on search
Set your (search) metrics, and live by them
Events and workshops
Haystack Conference US
Index Conference
DoorDash’s new search engine
DoorDash engineering blog written by Konstantin Shulgin, Satish Subhashrao Saley and Anish Walawalkar
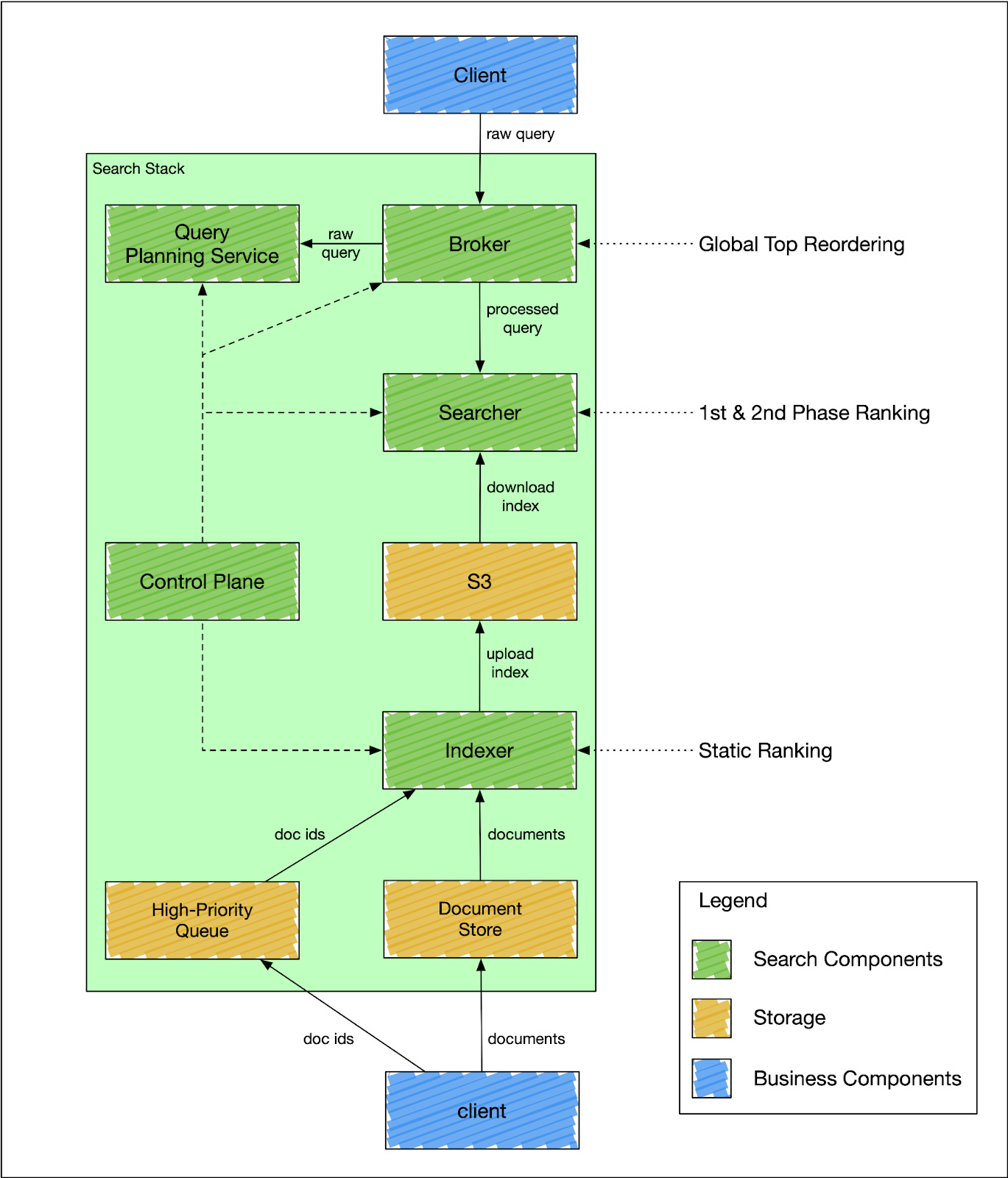
Search architecture diagram
DoorDash decided to move away from Elasticsearch to an in-house search engine using Apache Lucene. The main reasons for the new architecture revolved around challenges with the document-replication model and modeling complex relationships as search expanded beyond a store-based search experience to being able to search for both items and stores.
Separation of indexing and search
With Apache Lucene, DoorDash was able to adopt a segment-replication model, a replication model that makes it easier to separate read and write paths. The document-replication model in Elasticsearch requires that every document be indexed on all n replicas. So, if there are 3 replicas then the indexing operation occurs 3 times. Moving to the segment-replication model means that segment files are copied across replicas after indexing operations, lowering the amount of resources required for indexing as well as increasing indexing throughput.
Adopting a segment-replication model enabled an exciting new approach to search at DoorDash: the separation of the indexer and searcher services. This separation enables the services to scale independently. The indexer has nothing to do with replication and can focus on the indexing speed of bulk and single documents. The searcher can focus on search performance, without worrying about indexing operations.
Query engine
The team at DoorDash made search more efficient by creating their own query execution engine. The engine is designed to fan out search to all available shards and then merge the result sets. Parallel processing offers a more efficient approach to search then scanning through an index and all of its shards using a single processor. The query execution engine also built-in optimizations to find relevant indexes based on search parameters, enabling execution logic to reside within the search engine versus within the application code.
DoorDash built an internal query execution engine as it allows for general purpose search. A user or team can leverage the in-house search engine without needing to know the internal execution logic; users only need to possess an understanding of the business logic behind search.
For the query language, DoorDash decided to select a SQL-like API with parent-child and nested object join support. They also allow for the ability to execute computed fields at query time that contain complex ranking functions and business logic.
Multi-tenancy
The in-house solution is designed for a multi-tenant architecture where multiple teams can leverage the same search system with data and traffic isolation. They created a concept of a search stack where each team could specify their own index and schema based on their data and search patterns. This gave individual teams flexibility in the creation of their data model without dependency on the data model configured by other teams. Furthermore, DoorDash made it possible for teams to make any changes to their schema or undergo reindexing operations by introducing a control plane. The control plane allowed for search stack changes in isolation of changes to the rest of the search service, a pretty advanced feature.
Recommended Reads
Using small language models to improve search relevance at Swiggy
Swiggy engineering blog written by Adityakiran, Jose Matthew, Srinivas N and Jairaj Sathyanarayana
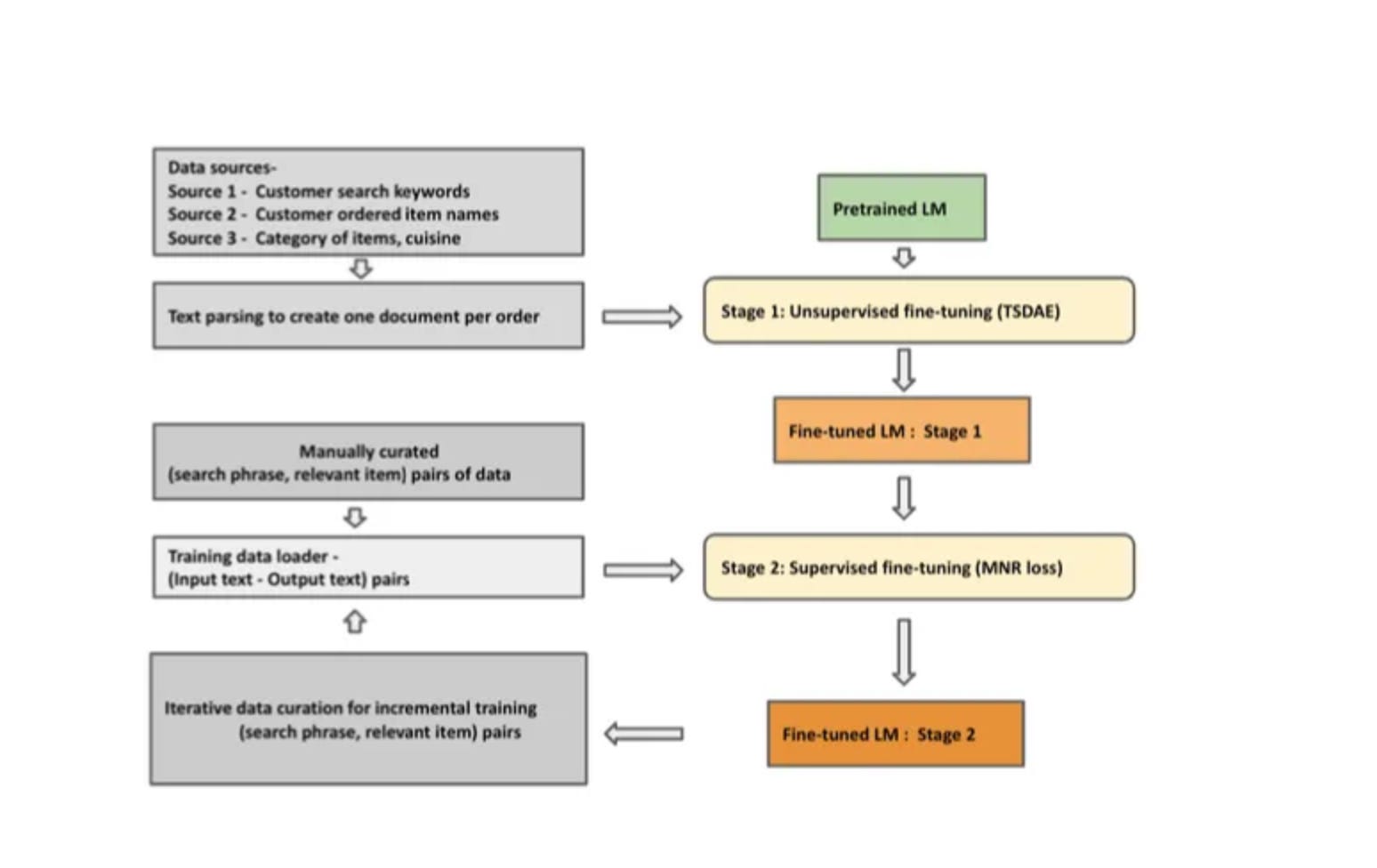
Overview of the two-stage fine-tuning approach
Discussion on the problem of matching search terms to dishes from restaurants in India. This is a problematic domain as languages and dish names change depending on the region. Swiggy describes how they solved problematic queries that do not contain an actual product but a question like "I just had a workout. Give me some suggestions". They used a two-stage fine-tuning approach of unsupervised based on historical searches and purchases as well as supervised using an internal taxonomy. The results are evaluated using a judgment list and a combination of the Mean Average Precision, Precision at 1 and 5.
RAFT for adding domain-specific knowledge to language models
Gorilla LLM from UC Berkeley Blog written by Tianjun Zhang, Shishir G. Patil, Kai Wen, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez, Cedric Vidal (Microsoft), Suraj Subramanian (Meta)
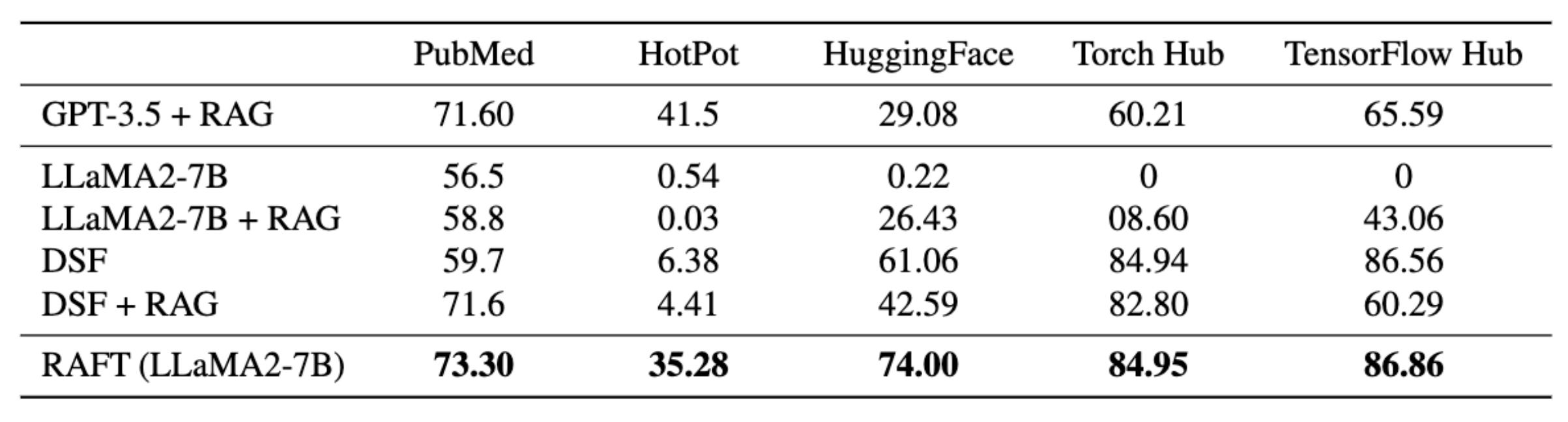
Results of RAFT on different benchmarks
RAFT stands for Retrieval-Augmented Fine Tuning, a new approach to find the best of both worlds of answering questions using an LLM with or without RAG. RAFT describes its approach using the comparison of an LLM with or without RAG to a student doing an exam. RAG being an open book exam, no RAG is a closed book exam. RAFT would be an open book exam, where the student studied the book before the exam extensively.
Evaluating GenAI products at LinkedIn
LinkedIn engineering blog written by Bonnie Barrilleaux
The “Write with AI” generative AI product feature to help users create their profile summary
Real-life case studies from LinkedIn on how GenAI products are evaluated using human reviews, in-product feedback and product usage metrics. Human reviews, while time intensive, are the gold standard with reviewers providing qualitative ratings on the experience as well as flagging hallucinations or bias that can erode user trust in products. In-product feedback and product usage metrics provide scalable ways to gauge member engagement and satisfaction.
Automate customer interaction using OpenAI Assistants
Luminus blog written by Jettro Coenradie
def create_assistant():
name = "Coffee Assistant"
instructions = ("You are a barista in a coffee shop. You"
"help users choose the products the shop"
"has to offer. You have tools available"
"to help you with this task. You can"
"answer questions of visitors, you should"
"answer with short answers. You can ask"
"questions to the visitor if you need more"
"information. more ...")
return Assistant.create_assistant(
client=client,
name=name,
instructions=instructions,
tools_module_name="openai_assistant.coffee.tools")Code to create the coffee assistant
An introduction to OpenAI assistants using a demo of a virtual coffee barista assistant. All the code is available in a GitHub repository. Using the code alongside the blog post gives you a jumpstart to creating your own AI assistant based on OpenAI.
Tips for search
Set your (search) metrics and live by them
Blog on search metrics written by Jettro Coenradie

Search metrics should be tied to business goals. For a grocery and delivery application, search and recommendations should help users find the most relevant products and add them to the cart as fast as possible. The metric for success might be time before a click on the basket to add the product to the cart. In contrast, a social media application wants search to help users find the most engaging content and join in on relevant conversations. The metric for success might be the amount of time on the site from a search. While GenAI introduces new, different metrics, metrics should continue to tie back to business goals.
Conferences and courses
Haystack Conference US
Haystack Conference is the conference for improving search relevance created by OpenSource Connections. Registration is now open for the conference on April 22, 23 and 24th in Charlottesville, VA USA. Talk all things search and relevance and tune into talks including:
Chat With Your Data - A Practical Guide to Production RAG Applications by Jeff Capobianco at Moodys
Learning to Rank at Reddit : A Project Retro by Doug Turnbull
Search Query Understanding with LLMs: From Ideation to Production by Ali Rokni at Yelp
Index Conference
Index is the conference for engineers building search, analytics and AI applications at scale created by Rockset on May 16th. Join virtually via zoom or in-person at the Computer History Museum in Mountain View, CA USA. Hear from engineers building applications at scale including:
How Uber Eats Built a Recommendation System Using Two Tower Embeddings by Bo Ling
How We Built Search for Go-to-Market Platforms at ZoomInfo by Ali Dasden, Joel Chou and Hasmik Sarkezians
Vector Search and the FAISS Library by Matthijs Douze at Meta